Pipeline
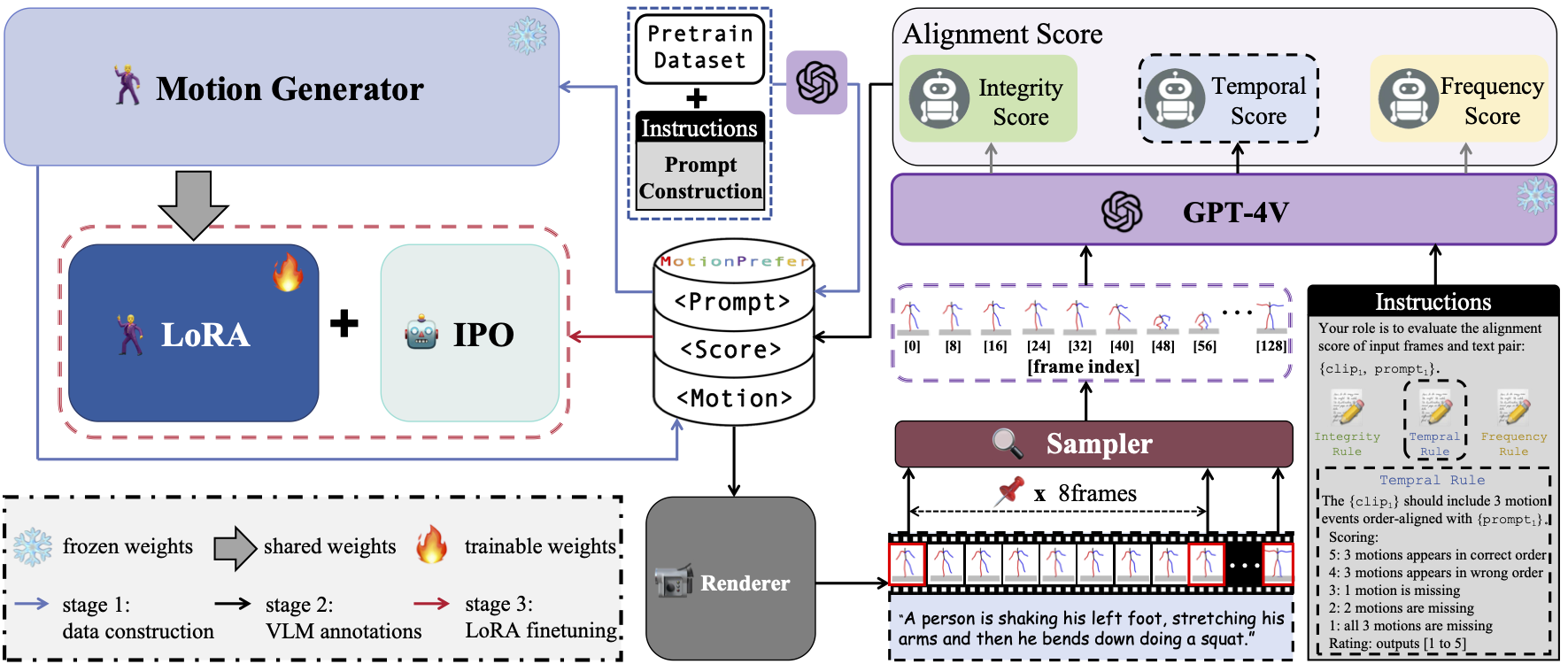
Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
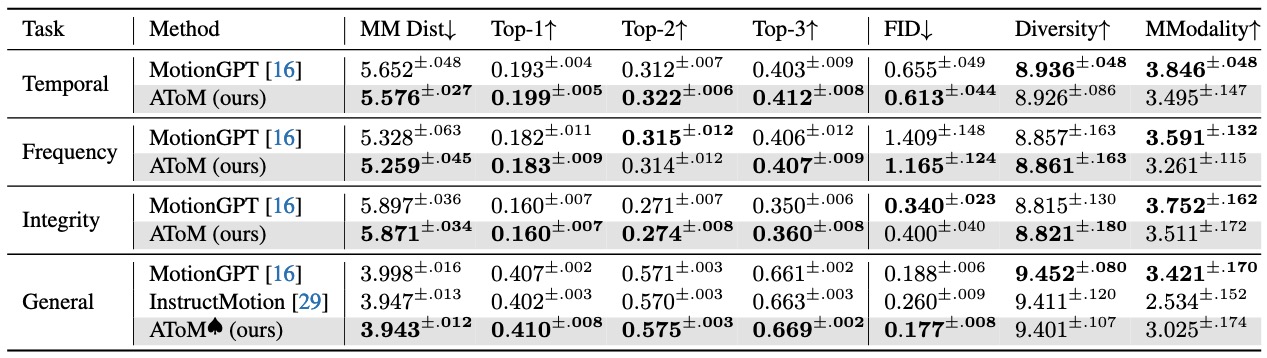
We conducted a quantitative experiment to evaluate the performance of AToM compared to baseline and existing methods. The results demonstrate that AToM achieves superior text-motion alignment, motion quality, and generative realism.
Frequency
Pretrain

Finetune

A person paces diagonally two times
Pretrain

Finetune

A person jumps forward one time
Pretrain

Finetune

A person who has his arms raised head high raises his arms
above his head and lowers them three times
Pretrain

Finetune
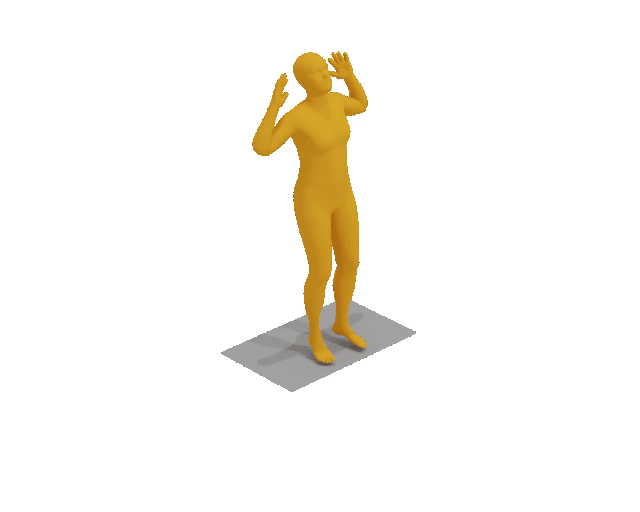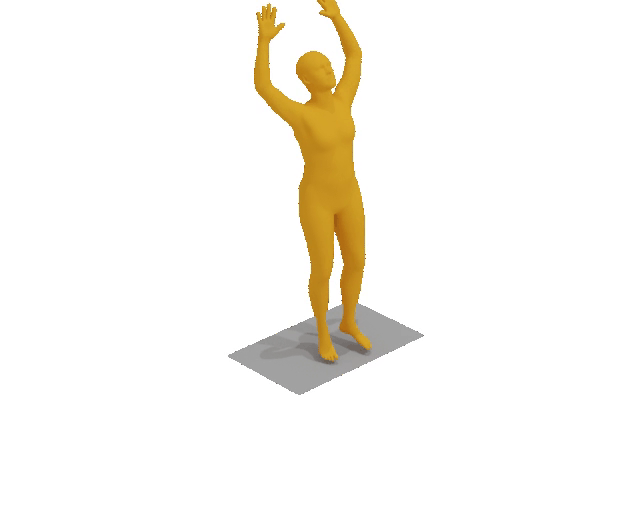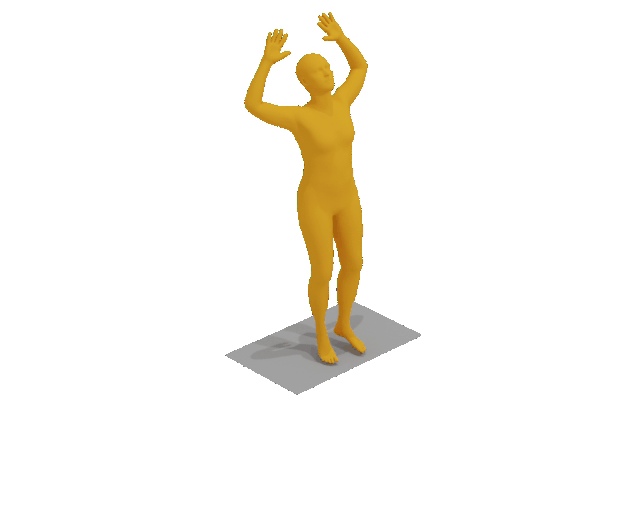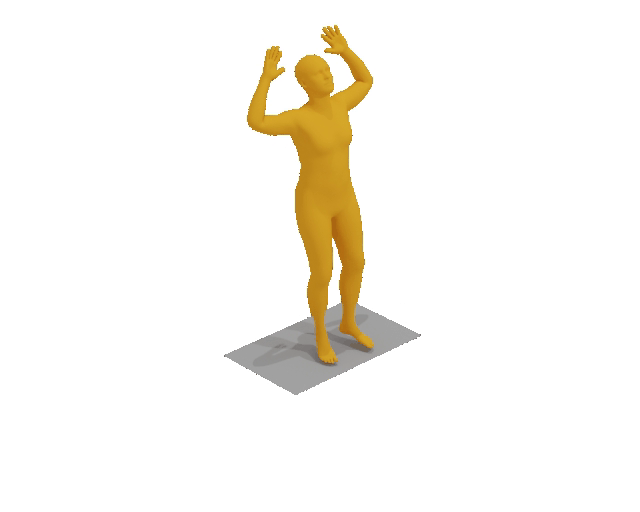
A man raises a bar over his head two times
Integrity
Pretrain

Finetune

A person steps back, jumps up , and walks forward
Pretrain

Finetune

The figure bends down, gets on their hands and knees,
and begins crawling to the left
Pretrain

Finetune

A person walks diagonally, stomping, uses hands
in a karate motion, and walks backward similarly.
Pretrain

Finetune

A person walks up stairs, turns right, and walks back down
Temporal
Pretrain

Finetune

A person walks forward, then is pushed to their
right and then returns to walking in the line
Pretrain

Finetune

a person takes a seat, appears to make a throwing
motion, and then stands up
Pretrain

Finetune

A person walks forwards doing ballet, then raising
one leg, then skipping and raising the other leg
Pretrain

Finetune

A person walks forwards doing ballet, skipping, then raising one leg, and then skipping and raising the other leg